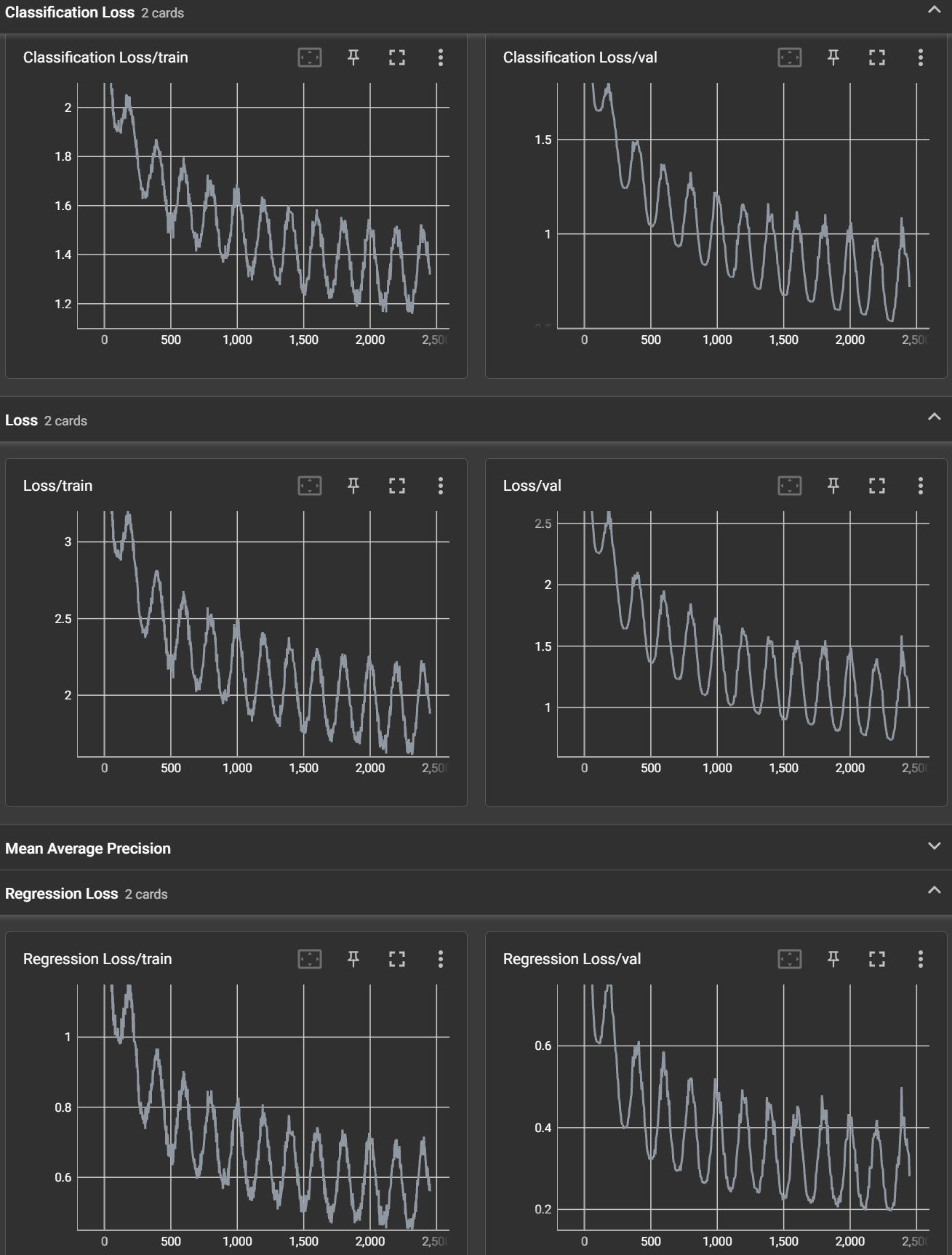
In terms of the actual loss values, it’s difficult to say what is “normal” as they can vary widely depending on the factors mentioned above. However, some practitioners have reported achieving classification losses around 1.0-2.0 and regression losses around 0.1-0.2 for SSD MobileNet v1 on common object detection datasets like COCO or Pascal VOC. Keep in mind that these are just rough estimates, and you should experiment with different loss functions and hyperparameters to find the best combination for your specific task.
For SSD MobileNet v2, the choice of classification and regression loss is similar to that of SSD MobileNet v1. The commonly used classification loss is the softmax cross-entropy loss, and the regression loss is usually the smooth L1 loss.
The actual loss values for SSD MobileNet v2 will depend on the specific dataset and other factors such as the size of the model and the amount of training data. However, some practitioners have reported achieving classification losses around 0.8-1.2 and regression losses around 0.1-0.2 for SSD MobileNet v2 on common object detection datasets like COCO or Pascal VOC.
a few general strategies that can help reduce loss:
- Increase the amount of training data: More training data can help the model learn a better representation of the problem, leading to better generalization and lower loss.
- Use data augmentation: Data augmentation can increase the diversity of the training data, which can help the model generalize better and reduce overfitting.
- Use a pre-trained model: A pre-trained model can provide a good starting point for training, allowing the model to benefit from the knowledge gained in training on a large and diverse dataset.
- Regularization: Regularization techniques like weight decay, dropout, and batch normalization can help prevent overfitting and reduce loss.
- Adjust hyperparameters: Hyperparameters like learning rate, batch size, and the number of layers can have a significant impact on the performance of a model. Experimenting with different hyperparameters can help find the optimal combination for a specific problem.
Remember, reducing loss is just one part of the training process, and it’s important to also evaluate the model’s performance on a validation set or through other metrics to ensure that it is performing well.
The loss of a model is a measure of how well the model is able to fit the training data. It is calculated as a numerical value that represents the difference between the model’s predicted outputs and the actual outputs. The goal of training a model is to minimize its loss by adjusting the model’s parameters and architecture.
While the loss and confidence rate are not directly connected, they can be related in certain situations. For example, if a model is overfitting the training data, its loss may be very low, but its confidence rate may be low as well because it is not able to generalize well to new, unseen data. Conversely, if a model has a high loss, it may also have a low confidence rate because it is not making accurate predictions.
Download free trial SSD Mobilenet model, which allows you to detect humans and forklift in industrial enviroment. Download detection model here.
Contact us if you need any help with sample image collection, image annotation, training SSD models or building machine vision solutions.
raul.orav@visioline.ee, gsm. +372 504 9966.